Convertitore di testo OCR¶
Lo strumento Convertitore di testo OCR analizza il contenuto di un’immagine, individua le aree con testo e converte il testo in file con caratteri modificabili e traducibili.
Lo strumento può eseguire in serie il riconoscimento ottico dei caratteri (OCR) sulle immagini e produrre la loro traduzione in più lingue, utilizzando un motore di traduzione in linea. Ti permette inoltre di revisionare il testo con l’ausilio del correttore ortografico e apportare le dovute correzioni.
Lo strumento usa il Tesseract, un motore avanzato di riconoscimento ottico dei caratteri disponibile per Linux, macOS e Windows.
Per eseguire la conversione dei testi, seleziona le immagini che includono testo da riconoscere e avvia lo strumento dal menu , oppure dall’icona Convertitore di testo OCR dalla scheda Strumenti nella barra laterale destra. Si aprirà la seguente finestra di dialogo:
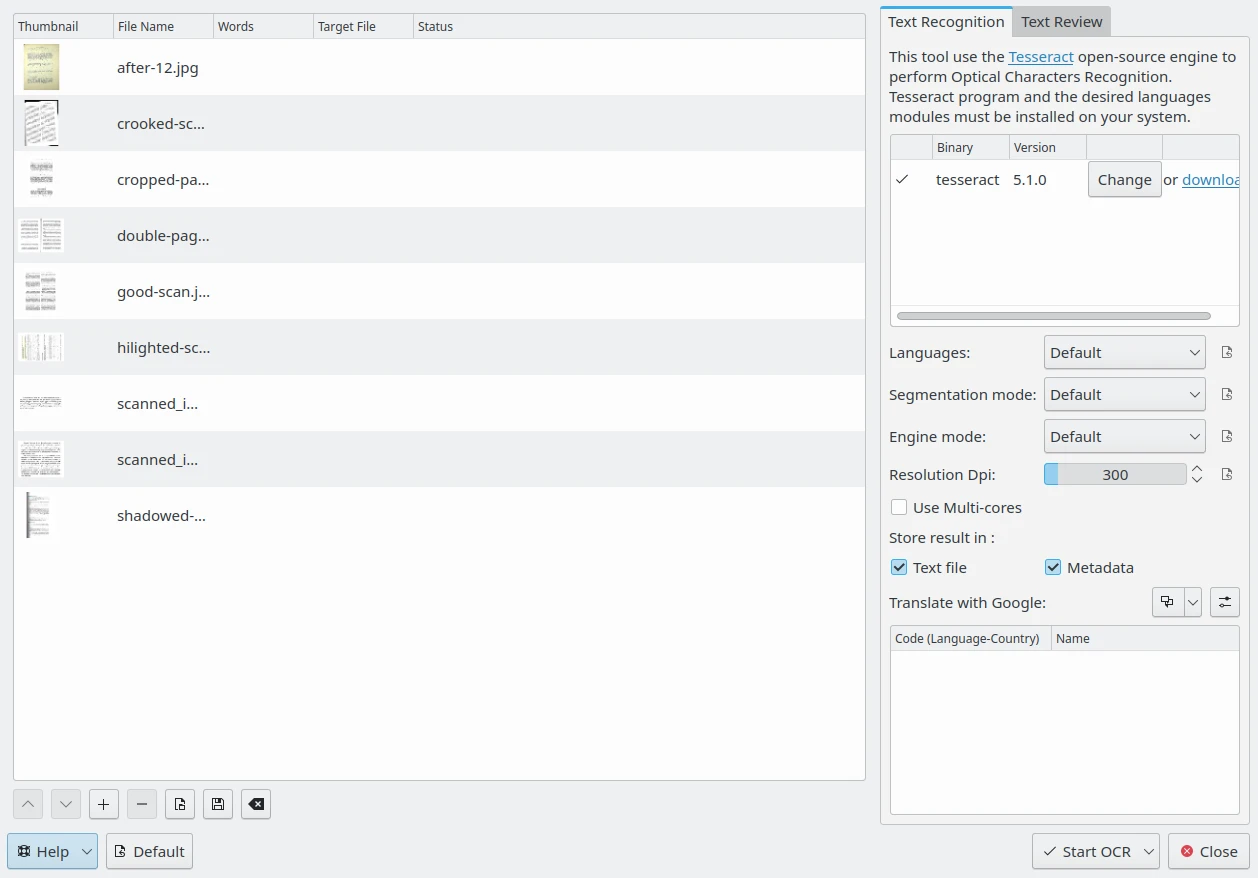
La finestra di dialogo del Convertitore di testo OCR di digiKam¶
A destra, la scheda Riconoscimento del testo se la versione dell’eseguibile del programma Tesseract viene rilevato dal sistema. Se l’eseguibile non è presente, dovrai installarlo. La porzione inferiore della scheda contiene le opzioni del Tesseract da impostare.
L’opzione Lingue specifica la lingua utilizzata per il riconoscimento. In modalità Predefinita, quando si elabora del testo digitale contenente più lingue, Tesseract è in grado di riconoscere automaticamente le lingue utilizzando gli alfabeti latini, come l’inglese o l’italiano, ma non è compatibile con le lingue che utilizzano ideogrammi, come il cinese o il giapponese. Puoi invece utilizzare la modalità Rilevamento orientazione e script oppure un modulo di lingua specifico, se disponibile.
L’opzione Modalità di segmentazione specificano la modalità di segmentazione della pagina da utilizzare per elaborare le immagini. Le scelte possibili sono:
Solo OSD: solo rilevamento orientazione e script (OSD).
Con OSD: segmentazione automatica di pagina con OSD.
Nessun OSD: segmentazione automatica di pagina ma senza OSD o OCR.
Predefinita: segmentazione automatica di pagina completa, ma senza OSD.
Col di testo: presume una singola colonna di testo di dimensioni variabili.
Allineato verticalmente: presume un singolo blocco uniforme di testo allineato verticalmente.
Blocco: presume un singolo blocco uniforme di testo.
Riga: tratta l’immagine come una singola riga di testo.
Parola: tratta l’immagine come una singola parola.
Parola cerchiata: tratta l’immagine come una singola parola in un cerchio.
Carattere: tratta l’immagine come un singolo carattere.
Testo sparso: trova quanto più testo possibile in nessun ordine particolare.
Testo sparso + OSD: testo sparso con OSD.
Riga grezza: tratta l’immagine come singola riga di testo, aggirando gli hack specifici di Tesseract.
Se vuoi approfondire la modalità di segmentazione di Tesseract puoi leggere questa esercitazione in linea.
L’opzione della Modalità motore specificano il motore interno OCR di Tesseract da usare durante l’elaborazione delle immagini. Le scelte possibili sono riportate sotto:
Obsoleto: solo motore obsoleto (motore più vecchio, non basato su una rete neurale).
LSTM: solo motore basato sulla rete neurale LSTM (apprendimento profondo Long Short-Term Memory).
Obsoleto + LSTM: sarà utilizzato sia il motore obsoleto, sia quello LSTM.
Predefinito: il valore predefinito, che lascia a Tesseract la scelta del motore migliore in base a ciò che c’è a disposizione.
L’opzione Risoluzione in DPI specifica la risoluzione delle immagini di ingresso, misurate in punti per pollice (Dot Per Inch, DPI).
Se è abilitata l’opzione Usa multi-core, il Tesseract elaborerà i file dall’elenco in parallelo.
L’opzione Salva il risultato in specifica la posizione in cui inserire il contenuto testuale riconosciuto da Tesseract durante l’elaborazione delle immagini. Le scelte possibili sono:
File di testo: memorizza il risultato OCR in un file di testo separato nella stessa cartella che contiene l’immagine elaborata.
Metadati: memorizza il risultato OCR in un tag XMP alternative-language nei metadati dell’immagine.
Nella parte inferiore di questa vista, il risultato dell’OCR può essere tradotto in diverse lingue utilizzando un motore di traduzione in linea. Puoi impostare più di una lingua di traduzione. Le traduzioni corrispondenti saranno salvate in file di testo separato o in voci aggiuntive di metadati, in base all’impostazione scelta nell’opzione Salva il risultato in. Per ulteriori dettagli sulle impostazioni di localizzazione vedi questa pagina del manuale.
La scheda Revisione del testo sul lato destro ti permette di modificare il risultato dell’OCR per ciascuna immagine elaborata con Tesseract. Seleziona un elemento dall’elenco a sinistra e il risultato dell’OCR sarà visualizzato in un editor di testo. Puoi modificare il testo o applicare la correzione ortografica, se necessario. Per ulteriori informazioni sulle impostazioni della correzione ortografica, vedi questa pagina del manuale.
Nella parte inferiore della finestra di dialogo, il pulsante Predefinito permette il ripristino ai valori predefiniti di tutte le opzioni. Il pulsante a tendina Avvia OCR inizializza l’elaborazione delle immagini attualmente selezionate dall’elenco oppure di tutte le immagini. Infine, il pulsante Chiudi ferma tutte le elaborazioni OCR, se in corso, e chiude la finestra di dialogo.
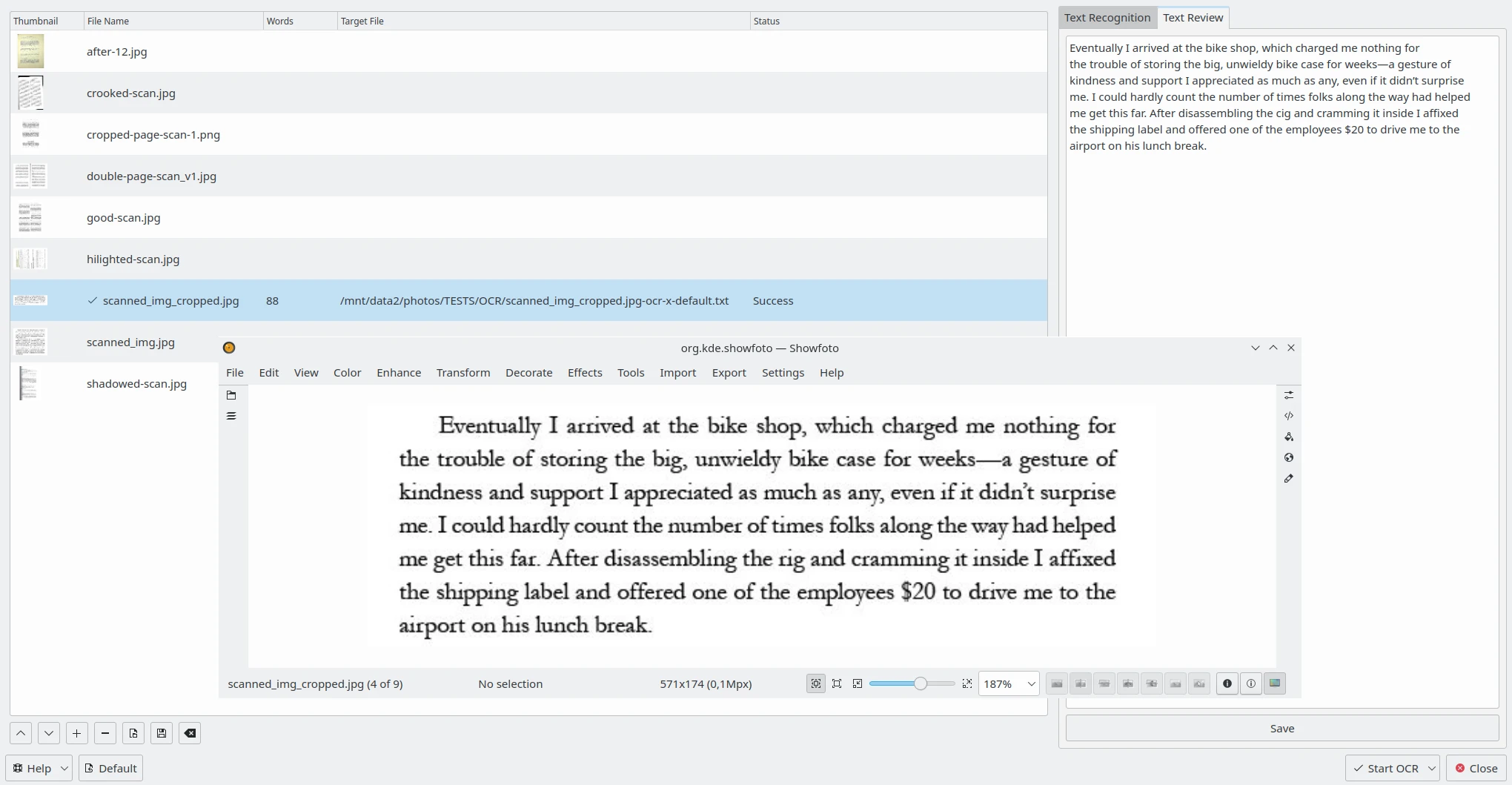
Il contenuto del convertitore di testo OCR di digiKam da revisionare sul lato destro, con la relativa immagine aperta in Showfoto¶