Conversor para texto por OCR¶
A ferramenta Converter para texto por OCR analisa o conteúdo de uma imagem, detecta áreas com texto e converte esse texto em arquivos de caracteres editáveis e traduzíveis.
A ferramenta pode realizar reconhecimento óptico de caracteres (OCR, sigla em inglês) em lote sobre imagens e produzir traduções em diversos idiomas usando um mecanismo de tradução online. Ela também permite que você revise o texto com o auxílio da verificação ortográfica e faça as correções necessárias.
A ferramenta usa o Tesseract, um poderoso mecanismo de reconhecimento óptico de caracteres de código aberto disponível para Linux, macOS e Windows.
Para realizar conversões de texto, selecione as imagens digitalizadas que incluem o texto a ser reconhecido e inicie a ferramenta no menu ou use o ícone Converter para texto por OCR na aba Ferramentas na barra lateral direita. A seguinte janela será exibida:
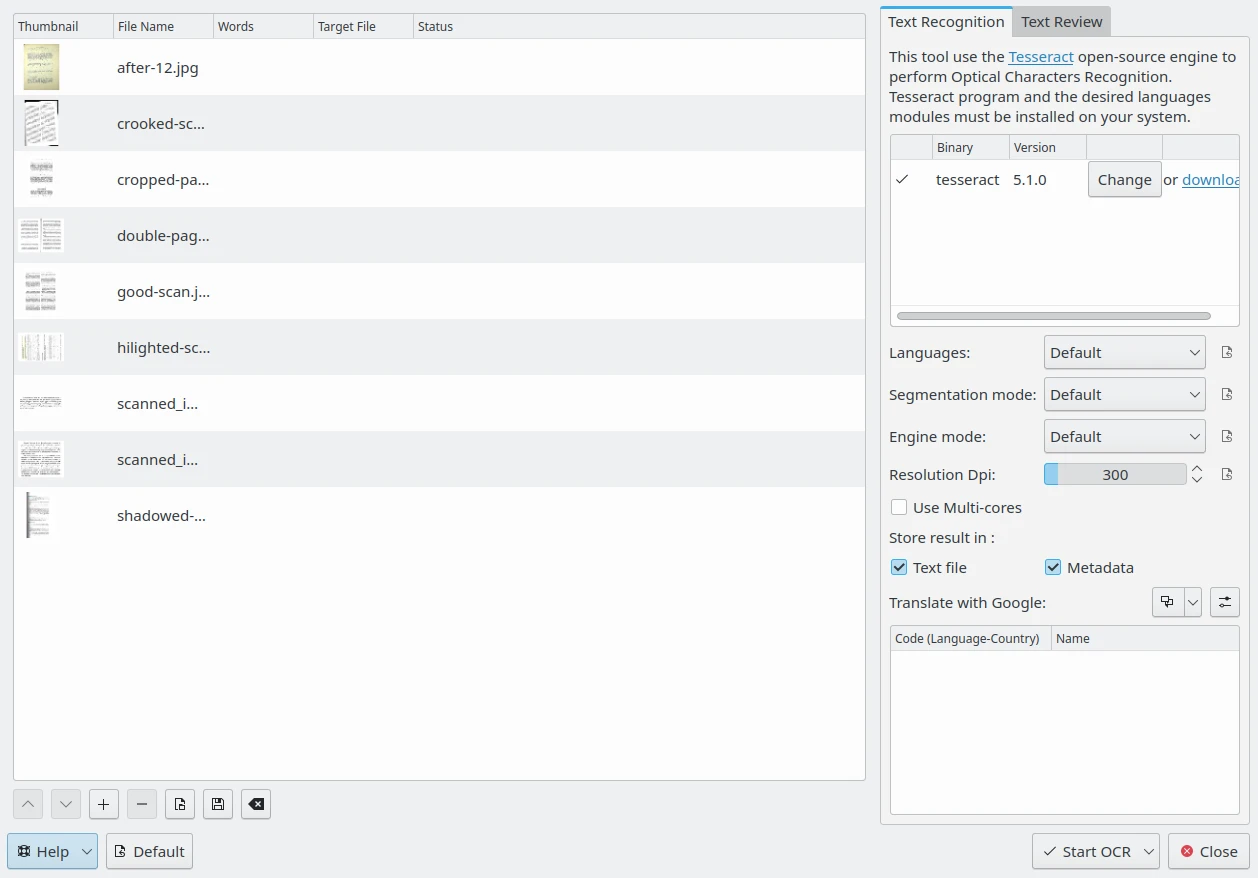
A janela do conversor para texto por OCR do digiKam¶
No lado direito, a aba Reconhecimento de texto indica se a versão binária do programa Tesseract foi detectada no seu sistema. Se o binário não estiver presente, você precisará instalá-lo no seu sistema. A parte inferior da aba Reconhecimento de texto contém as opções do Tesseract que você pode definir.
A opção Idiomas especifica o idioma usado para OCR. No modo Padrão, ao processar texto digital em vários idiomas, o Tesseract reconhece automaticamente idiomas que usam alfabetos latinos, como inglês ou francês, mas não é compatível com idiomas que usam hieróglifos, como chinês ou japonês. Você pode usar o modo Detecção de Orientação e de Escrita ou um módulo de idioma específico, se disponível.
A opção Modo de segmentação especifica o modo de segmentação de página do Tesseract a ser usado durante o processamento de imagens. As opções possíveis são:
OSD only: Somente Detecção de Orientação e de Escrita (OSD, sigla em inglês).
With OSD: Segmentação automática de páginas com OSD.
No OSD: Segmentação automática de páginas, mas sem OSD ou OCR.
Default: Segmentação de página totalmente automática, mas sem OSD.
Col of text: Assume uma única coluna de texto de tamanhos variáveis.
Vertically aligned: Assume um único bloco uniforme de texto alinhado verticalmente.
Block: Assume um único bloco uniforme de texto.
Line: Trata a imagem como uma única linha de texto.
Word: Trata a imagem como uma única palavra.
Word in circle: Trata a imagem como uma única palavra em um círculo.
Character: Trata a imagem como um único caractere.
Sparse text: Texto esparso. Encontre o máximo de texto possível, sem nenhuma ordem específica.
Sparse text + OSD: Texto esparso com OSD.
Raw line: Trata a imagem como uma única linha de texto, ignorando os truques específicos do Tesseract.
Se quiser mais detalhes sobre o modo de segmentação do Tesseract, leia este tutorial online.
A opção Modo do mecanismo especifica o mecanismo interno de OCR do Tesseract a ser usado durante o processamento de imagens. As opções possíveis estão listadas abaixo:
Legacy: Somente mecanismo legado (mecanismo mais antigo não baseado em uma rede neural).
LSTM: Somente mecanismo LSTM (Long Short-Term Memory deep-learning) de rede neural.
Legacy + LSTM: Serão utilizados mecanismos legados e LSTM.
Default: Valor padrão. Deixa o Tesseract escolher o melhor mecanismo com base no que está disponível.
A opção Resolução em dpi especifica a resolução das imagens de entrada, medida em pontos por polegada (DPI).
Se a opção Usar múltiplos núcleos estiver habilitada, o Tesseract processará os arquivos da lista em paralelo.
A opção Armazenar o resultado em especifica onde colocar o conteúdo de texto reconhecido pelo Tesseract durante o processamento de imagens. As opções possíveis são:
Arquivo de texto: Armazena o resultado do OCR em um arquivo de texto separado na mesma pasta da imagem processada.
Metadados: Armazena o resultado do OCR em uma etiqueta XMP de idioma alternativo nos metadados da imagem.
Na parte inferior desta visualização, o resultado do OCR pode ser traduzido para diferentes idiomas usando um mecanismo de tradução online. Você pode definir mais de um idioma de tradução para processar imagens. As traduções correspondentes serão hospedadas em arquivos de texto separados ou em entradas de metadados extras, dependendo da opção Armazenar o resultado em. Consulte esta página no manual para obter mais detalhes sobre as Configurações de localização.
A aba Revisão de texto à direita permite editar o resultado do OCR para cada imagem processada com o Tesseract. Selecione um item da lista à esquerda e o resultado do OCR será exibido em um editor de texto. Você pode editar o texto conforme necessário ou aplicar a verificação ortográfica. Consulte esta página no manual para obter mais detalhes sobre as Configurações de verificação ortográfica.
Na parte inferior da janela, o botão Padrão permite redefinir todas as opções para os valores padrão. O botão suspenso Iniciar OCR inicia o processamento das imagens selecionadas na lista ou de todos os itens. Por fim, o botão Fechar interromperá todos os processos de OCR, se houver, e fechará a janela.
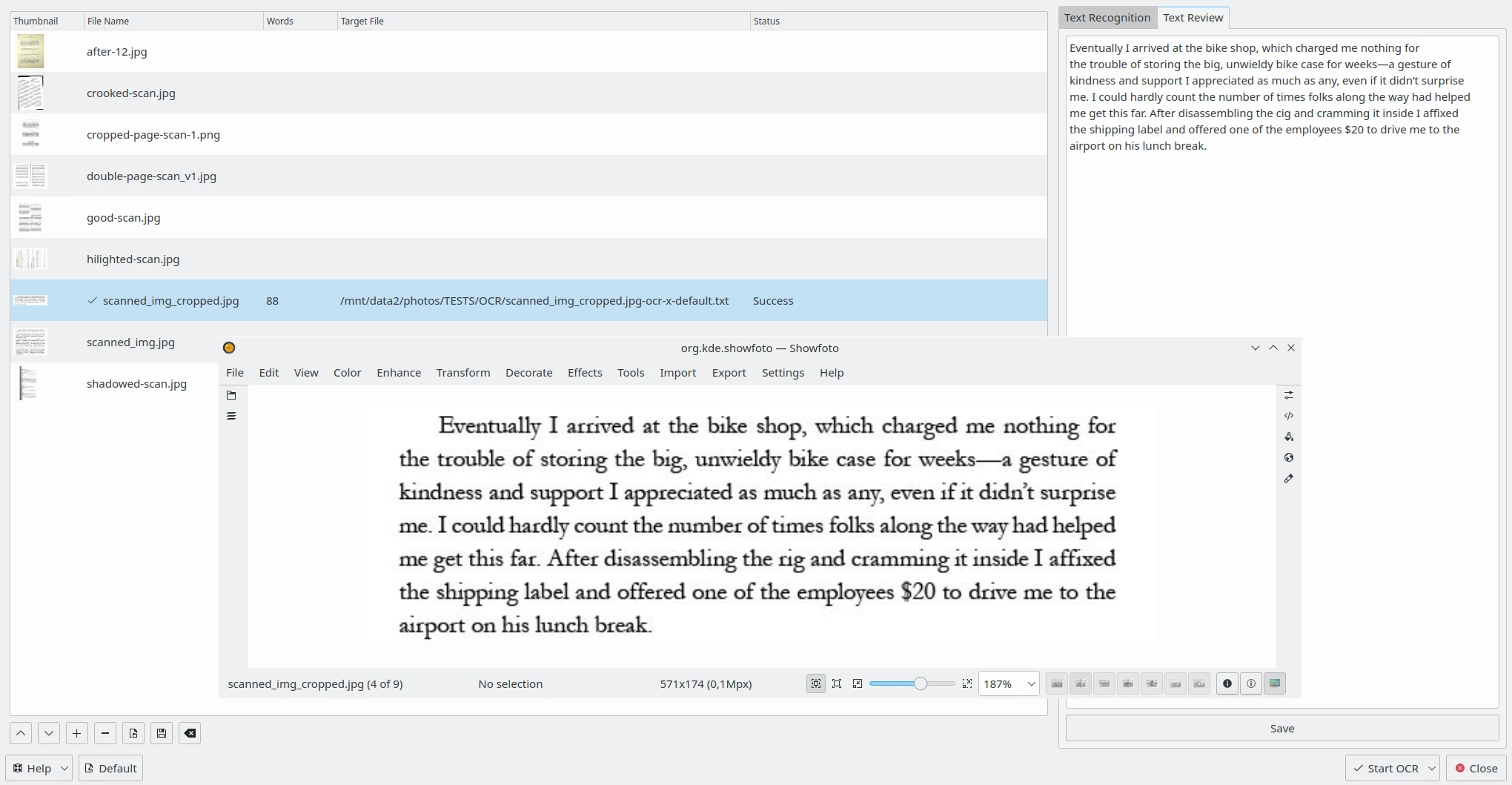
O conteúdo para revisão do conversor para texto por OCR do digiKam no lado direito com a imagem correspondente aberta no Showfoto¶