Перетворювач зображення на текст¶
Засіб розпізнавання тексту є інструментом для обробки вмісту зображення та виявлення областей з текстом з метою перетворення цих областей на придатні до редагування і перекладу текстові файли.
Інструмент може виконувати пакетне розпізнавання символів на зображеннях і виконувати переклад тексту багатьма мовами за допомогою інтернет-рушія перекладу. Також він надає вам змогу рецензування тексту та внесення змін і пропонує послуги з перевірки правопису.
Інструмент використовує Tesseract, потужний рушій розпізнавання символів з відкритим кодом, який доступний у Linux, macOS і Windows.
Щоб виконати розпізнавання тексту, виберіть скановані зображення, на яких є текст для розпізнавання, і запустіть інструмент за допомогою пункту меню або скористайтеся піктограмою Перетворювач зображення на текст з вкладки Інструменти на правій бічній панелі. Має з’явитися таке діалогове вікно:
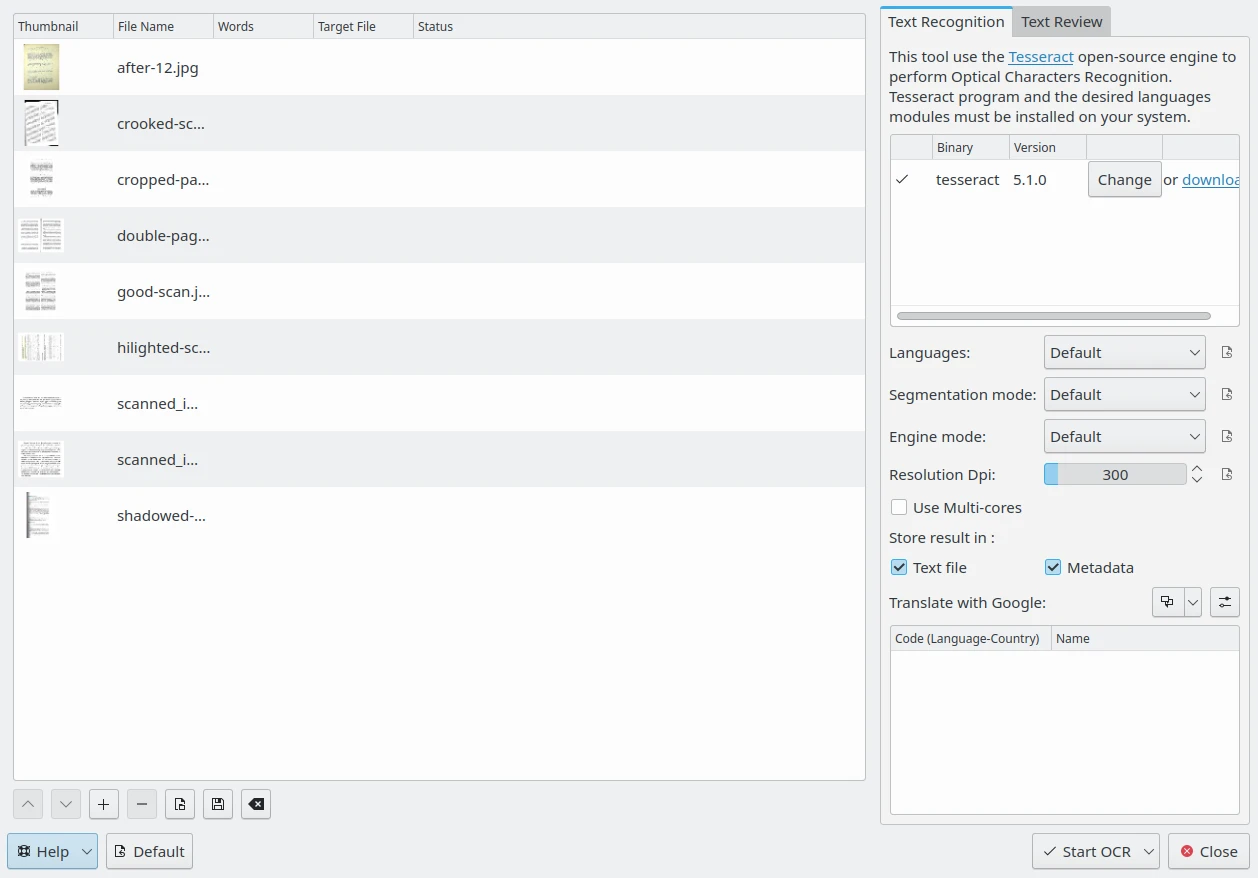
Вікно засобу розпізнавання тексту у digiKam¶
У правій частині вікна на вкладці Розпізнавання тексту у верхній частині панелі буде показано версію двійкової програми Tesseract, яку виявлено у вашій системі. Якщо такої програми виявлено не буде, вам слід встановити її у вашій системі. Нижче можна налаштувати параметри Tesseract для обробки зображень і розпізнавання тексту.
Параметр Мови визначає мову, яку буде використано для розпізнавання тексту. У Типовому режимі при обробці цифрового тексту декількома мовами Tesseract може автоматично розпізнавати мови, у яких використовують латинські абетки, зокрема англійську або французьку, але ця система не сумісна із мовами, де використовують ієрогліфічні системи запису, зокрема китайською або японською. Ви можете скористатися режимом Виявлення орієнтації та писемності або вказати модуль певної мови, якщо такий доступний.
Параметри розділу Режим поділу визначають режим поділу Tesseract під час обробки зображень. Можливі варіанти:
OSD only: лише виявлення орієнтації і писемності.
With OSD: автоматична сегментація сторінки із виявленням орієнтації.
No OSD: автоматична сегментація сторінки, але без визначення орієнтації або оптичного розпізнавання.
Default: повністю автоматичний поділ сторінки, але без визначення орієнтації та писемності.
Col of text: припускати текст одинарним стовпчиком змінної ширини.
Vertically aligned: припускати текст одним однорідним вертикально вирівняним блоком.
Block: припускати текст одним однорідним блоком.
Line: вважати зображення окремим рядком тексту.
Word: вважати зображення окремим словом.
Word in circle: вважати зображення окремим словом у колі.
Character: вважати зображення одинарним символом.
Sparse text: розріджений текст. Знайти якомога більше тексту у певному порядку.
Sparse text + OSD: розріджений текст із визначенням орієнтації і писемності.
Простий рядок: вважати зображення одним рядком тексту, не використовувати обхідних алгоритмів, які є специфічними для Tesseract.
Якщо ви хочете дізнатися більше про режим поділу у Tesseract, можете почитати цей інтернет-підручник.
Параметр Режим рушія визначає внутрішній рушій розпізнавання тексту Tesseract, який буде використано для обробки зображень. Можливі варіанти:
Legacy: лише застарілий рушій (рушій, який не засновано на нейронній мережі).
LSTM: лише рушій нейронної мережі LSTM (глибинне навчання на основі довгої короткострокової пам’яті).
Legacy + LSTM: використати одразу застарілий рушій і рушій LSTM.
Default: типове значення. Надати змогу Tesseract вибрати найкращий рушій на основі доступних даних.
Параметр списку Роздільність визначає роздільність вхідних зображень у крапках на дюйм.
Якщо позначено пункт Використовувати декілька ядер, Tesseract виконає паралельну обробку файлів зі списку.
За допомогою пункту Місце зберігання результатів можна задати місце, куди буде записано розпізнані Tesseract під час обробки зображень фрагменти тексту. Можливі варіанти:
Текстовий файл: зберегти результат розпізнавання в окремому текстовому файлі у тому самому каталозі, що і оброблене зображення.
Метадані: зберегти результат розпізнавання у мітці XMP з альтернативними мовами у метаданих зображення.
За допомогою нижньої частини цієї панелі результат розпізнавання тексту може бути перекладено різними мовами з використанням інтернет-рушія перекладу. Ви можете визначити декілька мов перекладу для обробки зображень. Відповідні переклади буде збережено до окремих текстових файлів або додаткових записів метаданих, залежно від значення параметра Місце зберігання результатів. Див. цю сторінку підручника, щоб дізнатися більше про Параметри локалізації.
За допомогою вкладки Рецензування тексту у правій частині можна редагувати результат розпізнавання тексту для кожного зображення, яке оброблено Tesseract. Виберіть один запис зі списку ліворуч, і у текстовому редакторі буде показано результат розпізнавання. Ви можете, якщо потрібно, виправити текст або застосувати засіб перевірки правопису. Див. цю сторінку підручника щоб дізнатися більше про Параметри перевірки правопису.
У нижній частині діалогового вікна розташовано кнопку Типовий, за допомогою якої можна відновити типові значення для усіх параметрів обробки. За допомогою спадного списку Почати розпізнавання можна вибрати між обробкою поточних позначених зображень зі списку і обробкою усіх зображень. Нарешті, за допомогою кнопки Закрити можна перервати роботу усіх процесів розпізнавання, якщо такі запущено, і закрити діалогове вікно.
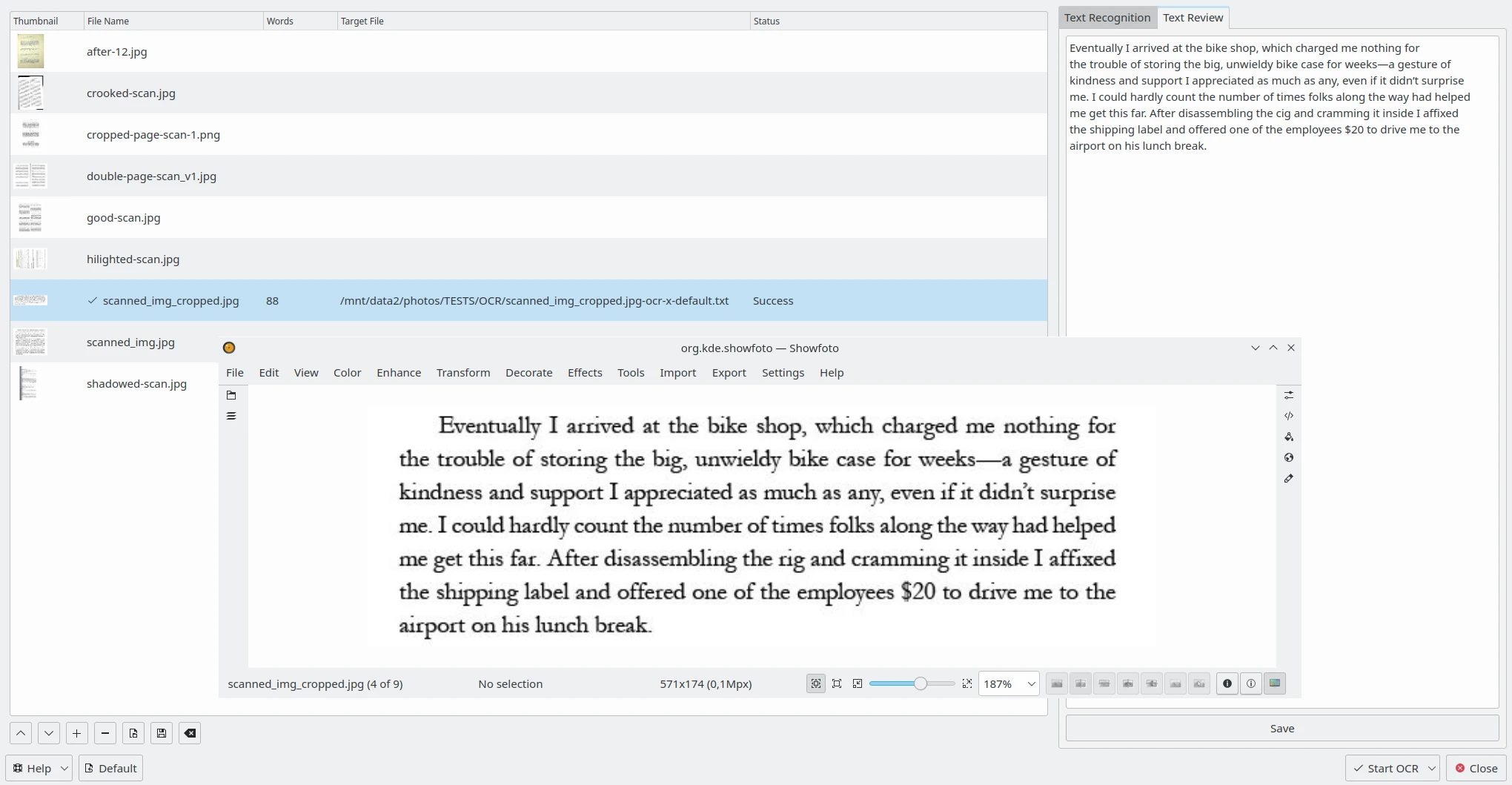
Рецензування даних засобу розпізнавання тексту digiKam праворуч від відкритого у Showfoto відповідного зображення¶