Atribuição automática de etiquetas¶
As opções de manutenção do digiKam para atribuir etiquetas automaticamente¶
A ferramenta para Atribuir etiquetas automaticamente escaneia as imagens da sua coleção usando uma rede neural treinada para identificar objetos comuns. Os objetos identificados pela rede neural são então usados para marcar cada imagem. Após a conclusão da varredura, você pode pesquisar em seu banco de dados por imagens que contenham um pássaro, uma bola ou um carro. As etiquetas geradas pelo processo de atribuição automática de etiquetas estarão sob a etiqueta auto na vista de etiquetas para diferenciá-las dos etiquetas que foram atribuídas manualmente.
Este processo também pode ser acessado na vista de Etiquetas por meio do botão Analisar para etiquetamento automático. Para obter mais informações sobre as opções de Etiquetamento automático, consulte a seção Vista de etiquetas deste manual.
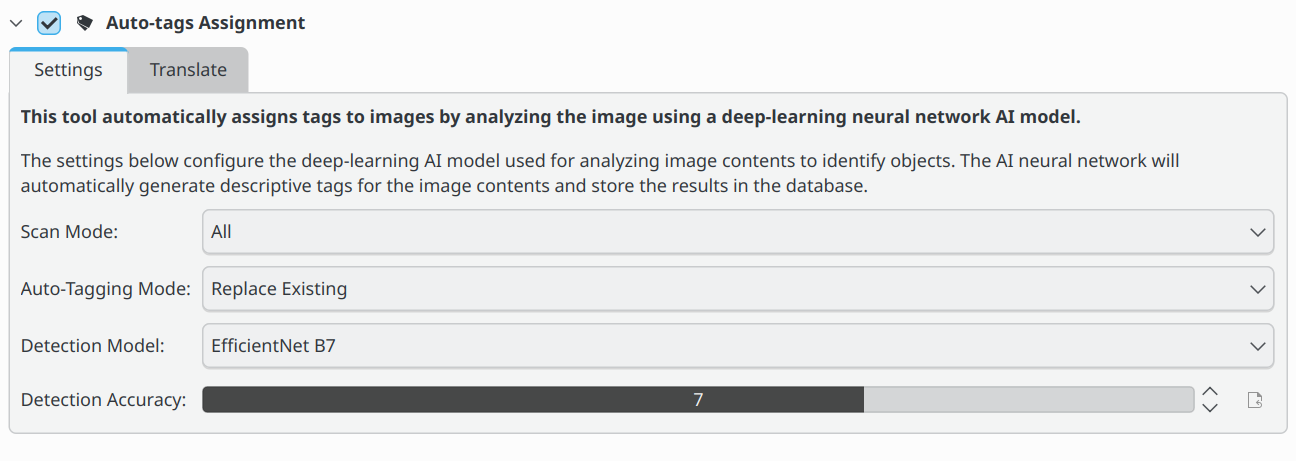
Para o etiquetamento automático, há quatro configurações que o usuário pode ajustar para controlar como o digiKam detecta e marca objetos em uma imagem.
Modo de análise: O modo de análise determina se o digiKam analisará todas as imagens ou apenas aquelas que não possuem uma etiqueta auto já atribuída. A etiqueta auto é atribuída a imagens que foram marcadas automaticamente. A etiqueta auto não é atribuída a imagens que foram marcadas manualmente.
Modo de etiquetamento automático: Ao aplicar etiquetas automáticas, você pode escolher entre Atualizar e Substituir existentes. Atualizar adicionará quaisquer novas etiquetas automáticas às etiquetas existentes na imagem. Substituir existentes removerá todas as etiquetas automáticas existentes e as substituirá pelas etiquetas detectadas pela verificação atual. Quaisquer etiquetas que não estejam na etiqueta auto não serão afetadas. Esta configuração é útil se você quiser executar várias verificações com configurações diferentes e combinar os resultados.
Modelo de detecção: O modelo de detecção é a rede neural usada para detectar objetos na imagem. O modelo padrão é o EfficientNet B7. O modelo EfficientNet B7 é um modelo de uso geral que pode detectar 1.000 objetos e cenas diferentes. O modelo YOLOv11-Nano é mais rápido e usa menos memória do que o modelo EfficientNet B7. O modelo YOLOv11-Nano é recomendado para usuários com memória limitada ou processadores mais lentos, e o YOLOv11-XLarge é recomendado para usuários com mais memória e processadores mais rápidos. Ambos os modelos YOLOv11 são treinados para detectar 80 objetos diferentes com base no conjunto de dados COCO.
Precisão: Configurações de precisão mais baixas podem detectar mais objetos em uma imagem, mas também aumentam o número de objetos identificados incorretamente (falsos positivos). A configuração padrão de 7 é recomendada para uso normal.
Enquanto o processo de atribuição automática de etiquetas estiver em andamento, um indicador de progresso será exibido no canto inferior direito da janela principal.