Assegnazione tag automatici¶
Le opzioni di manutenzione di digiKam per l’assegnazione di tag automatici¶
Assegnazione tag automatici analizza le immagini della tua raccolta utilizzando una rete neurale addestrata a identificare gli oggetti comuni. Gli oggetti identificati dalla rete neurale vengono quindi utilizzati per assegnare tag a ciascuna immagine. Quando l’analisi viene completata, è possibile ricercare nella banca dati le immagini che contengono un uccello, una palla o un’autovettura. I tag generati dal processo di assegnazione automatica dei tag si troveranno sotto il tag automatico nella vista Tag in modo da distinguerli dai tag che sono stati assegnati manualmente.
Puoi accedere a questo processo dalla vista Tag tramite il pulsante Analisi tag automatici. Per ulteriori informazioni sulle opzioni dei tag automatici vedi il capitolo Vista dei tag di questo manuale.
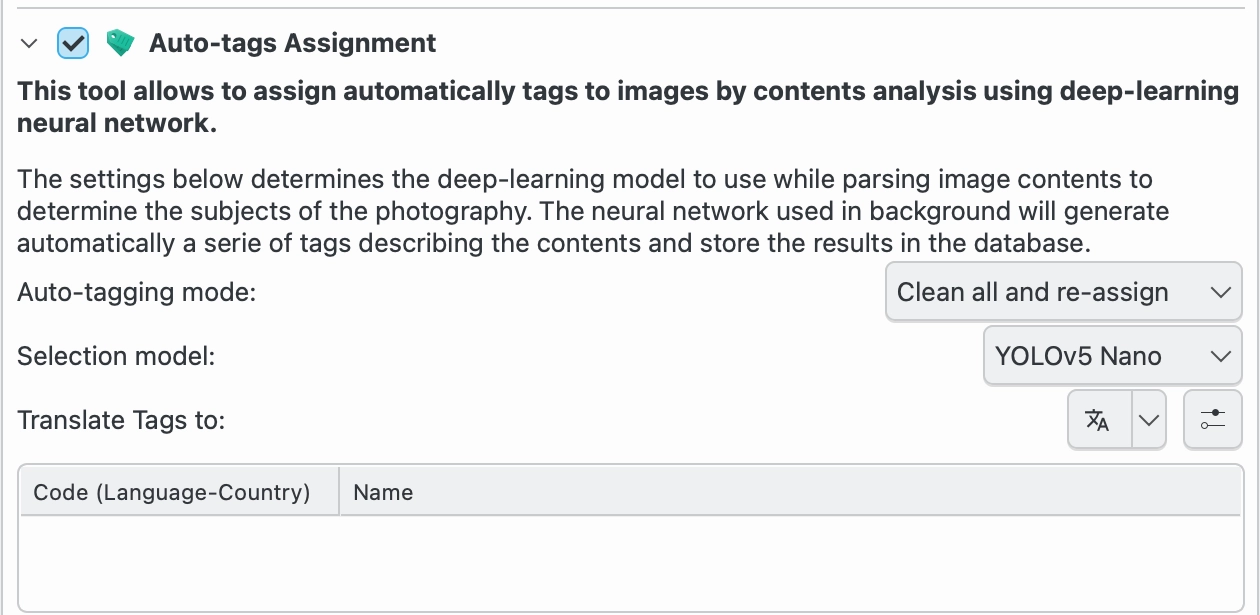
Per l’attribuzione di tag automatici sono regolabili quattro impostazioni per controllare come digiKam rileva e attribuisce tag agli oggetti in un’immagine.
Modalità di analisi: questa modalità determina se digiKam analizzerà tutte le immagini o solo quelle che non hanno già assegnato un tag automatico. Il tag automatico viene assegnato alle immagini che sono state analizzate per l’attribuzione di tag automatici. Il tag automatico non viene assegnato alle immagini i cui tag sono stati attribuiti manualmente.
Modalità attribuzione tag automatici: quando applichi tag automatici, puoi scegliere tra Aggiorna e Sostituisci esistenti. Aggiorna aggiungerà tutti i tag automatici nuovi ai tag esistenti nell’immagine. Sostituisci esistenti rimuoverà tutti i tag automatici esistenti e li sostituirà con quelli individuati dall’attuale analisi. I tag al di fuori del tag automatico non verranno modificati. Questa impostazione è utile se vuoi avviare più analisi con impostazioni differenti e combinarne i risultati.
Modello di rilevamento: è la rete neurale per il rilevamento degli oggetti nell’immagine. Il modello predefinito è EfficientNet B7. Questo è un modello di tipo generale in grado di rilevare 1.000 oggetti e scene diversi. Il modello YOLOv11-Nano è più veloce e utilizza meno memoria del modello EfficientNet B7. YOLOv11-Nano è consigliato agli utenti con memoria del computer limitata o processori lenti, mentre YOLOv11-XLarge è consigliato agli utenti con memoria superiore e processori più veloci. Entrambi i modelli YOLOv11 sono addestrati per individuare 80 oggetti differenti basati sull’insieme di dati COCO.
Accuratezza: impostazioni di accuratezza più basse possono individuare più oggetti in un’immagine, ma aumenteranno anche il numero di oggetti identificati in modo scorretto (falsi positivi). L’impostazione predefinita 7 è consigliata per un uso normale.
Durante il processo di assegnazione dei tag automatici, viene visualizzato un indicatore di avanzamento nell’angolo inferiore destro della finestra principale.