Convertidor de text OCR¶
L'eina Convertidor de text OCR analitza el contingut d'una imatge, detecta àrees amb text, i converteix aquest text en fitxers de caràcters editables i traduïbles.
L'eina pot efectuar lots de reconeixement òptic de caràcters (OCR) sobre les imatges i produir traduccions en molts idiomes mitjançant un motor de traducció en línia. També permet revisar el text amb l'ajuda de la verificació ortogràfica, i fer correccions si cal.
L'eina utilitza el Tesseract, un motor potent de reconeixement òptic de caràcters de codi obert disponible per al Linux, macOS i Windows.
Per a realitzar conversions de text, seleccioneu les imatges escanejades que inclouen el text que voleu reconèixer, i inicieu l'eina des del menú , o utilitzeu la icona Convertidor de text OCR de la pestanya Eines a la barra lateral dreta. Apareixerà el diàleg següent:
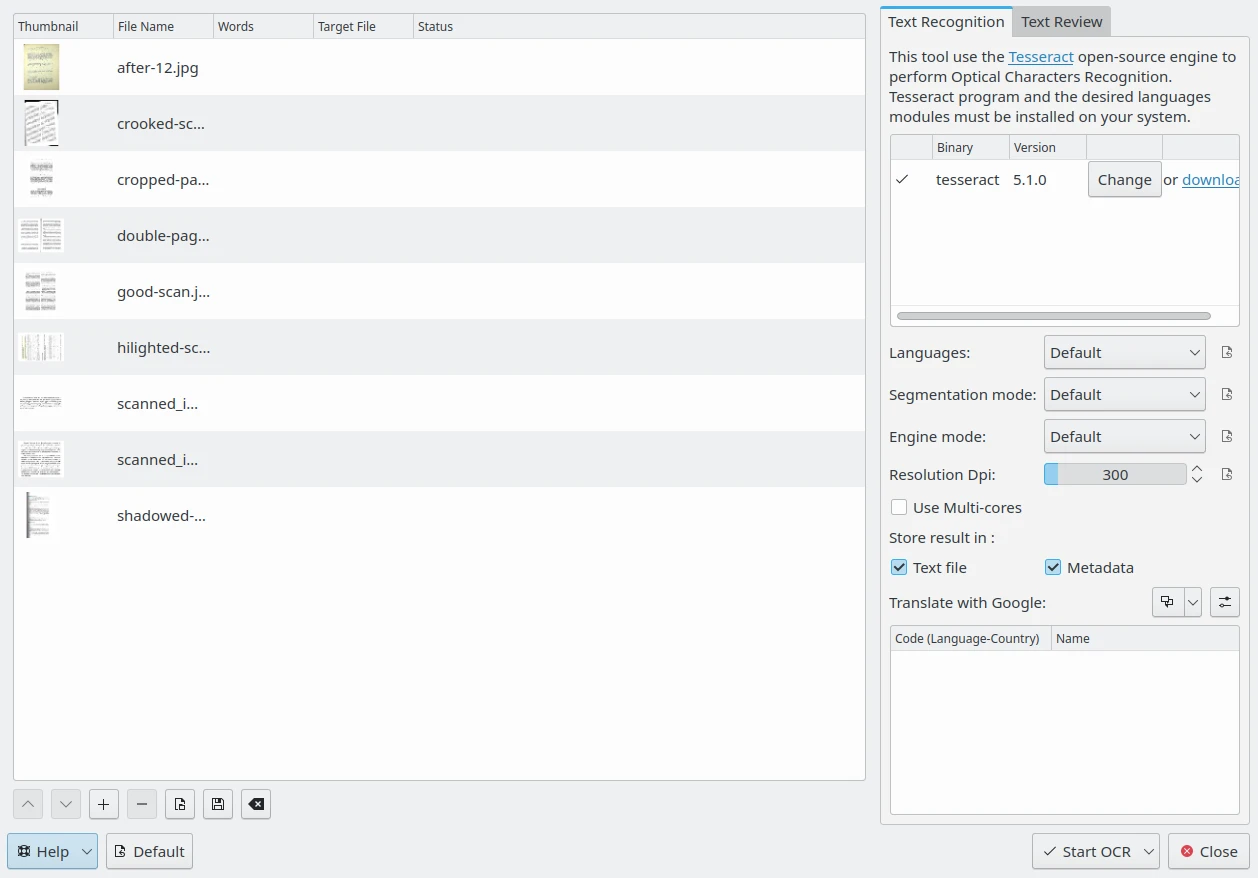
El diàleg del convertidor de text OCR del digiKam¶
A la part dreta, la pestanya Reconeixement de text indica si s'ha detectat la versió del programa binari Tesseract en el sistema. Si no n'hi ha cap, haureu d'instal·lar-lo al sistema. La part inferior de la pestanya Reconeixement de text conté les opcions del Tesseract que podeu establir.
L'opció de configuració Idiomes especifica l'idioma utilitzat per a l'OCR. En el mode Predeterminat, quan es processi el text digital amb múltiples idiomes, el Tesseract podrà reconèixer automàticament els idiomes que utilitzen alfabets llatins com l'anglès o el francès, però no admet els idiomes que utilitzen jeroglífics com el xinès o el japonès. En el seu lloc podreu utilitzar el mode Detecció de l'orientació i del sistema d'escriptura o si està disponible, un mòdul d'idioma específic.
L'opció Mode de segmentació especifica el mode de segmentació de pàgina que s'utilitzarà el Tesseract durant el processament de les imatges. Les opcions possibles són:
Només OSD: només orientació i detecció del sistema d'escriptura (OSD).
Amb OSD segmentació automàtica de pàgines amb OSD.
Sense OSD: segmentació automàtica de pàgines, però sense OSD ni OCR.
Predeterminat: segmentació de pàgines totalment automàtica, però sense OSD.
Columna de text: assumirà una sola columna de text de mida variable.
Alineat verticalment: assumirà un sol bloc uniforme de text alineat verticalment.
Bloc: assumirà un sol bloc uniforme de text.
Línia: tractarà la imatge com una sola línia de text.
Paraula: tractarà la imatge com una sola paraula.
Paraula encerclada: tractarà la imatge com una sola paraula en un cercle.
Caràcter: tractarà la imatge com un sol caràcter.
Text dispers: trobarà la quantitat més gran possible de text sense cap ordre en particular.
Text dispers + OSD: hi ha text dispers i empra OSD.
Línia sense processar: tractarà la imatge com una sola línia de text, passant per alt els hacks específics del Tesseract.
Per a obtenir més detalls sobre el mode de segmentació del Tesseract, podeu llegir aquesta guia d'aprenentatge en línia.
L'opció Mode del motor especifica el motor d'OCR intern del Tesseract que s'utilitzarà quan es processin les imatges. Les opcions possibles es llisten a continuació:
Antic: només el motor antic (el motor anterior no basat en una xarxa neuronal).
LSTM: només el motor de xarxa neuronal LSTM (aprenentatge profund de memòria a llarg i curt termini).
Llegat + LSTM: s'utilitzaran els motors heretats i LSTM.
Predeterminat: és el valor predeterminat. Es deixa que el Tesseract esculli el millor motor en funció dels que hi ha disponibles.
L'opció Resolució ppp especifica la resolució de les imatges d'entrada, mesurades en punts per polzada (PPP).
Si l'opció Usa múltiples nuclis està activada, el Tesseract processarà els fitxers de la llista en paral·lel.
L'opció Emmagatzema el resultat a especifica on col·locar el contingut del text reconegut pel Tesseract mentre processa les imatges. Les opcions possibles són:
Fitxer de text: emmagatzemarà el resultat de l'OCR en un fitxer de text separat en el mateix directori que la imatge processada.
Metadades: emmagatzemarà el resultat de l'OCR en una etiqueta XMP d'idioma alternatiu en les metadades de la imatge.
A la part inferior d'aquesta vista, el resultat de l'OCR es pot traduir a idiomes diferents utilitzant un motor de traducció en línia. Podreu configurar més d'un idioma de traducció per a processar les imatges. Les traduccions corresponents s'allotjaran en fitxers de text separats o en entrades de metadades addicionals segons l'opció Emmagatzema el resultat a. Per a obtenir més detalls sobre la Configuració de la traducció vegeu aquesta pàgina del manual.
La pestanya Revisió del text a la part dreta permet editar el resultat de l'OCR de cada imatge processada amb el Tesseract. Seleccioneu un element de la llista en el costat esquerre i el resultat de l'OCR es mostrarà en un editor de text. Si cal, podreu corregir el text o aplicar la revisió ortogràfica. Per a obtenir més detalls sobre la Configuració del corrector ortogràfic, vegeu aquesta pàgina del manual.
A la part inferior del diàleg, el botó Predeterminat permet restablir totes les opcions als valors predeterminats. El botó desplegable Inicia l'OCR inicia el processament de les imatges seleccionades des de la llista o de tots els elements. Finalment, el botó Tanca aturarà tots els processos de l'OCR, si n'hi ha cap, i tancarà el diàleg.
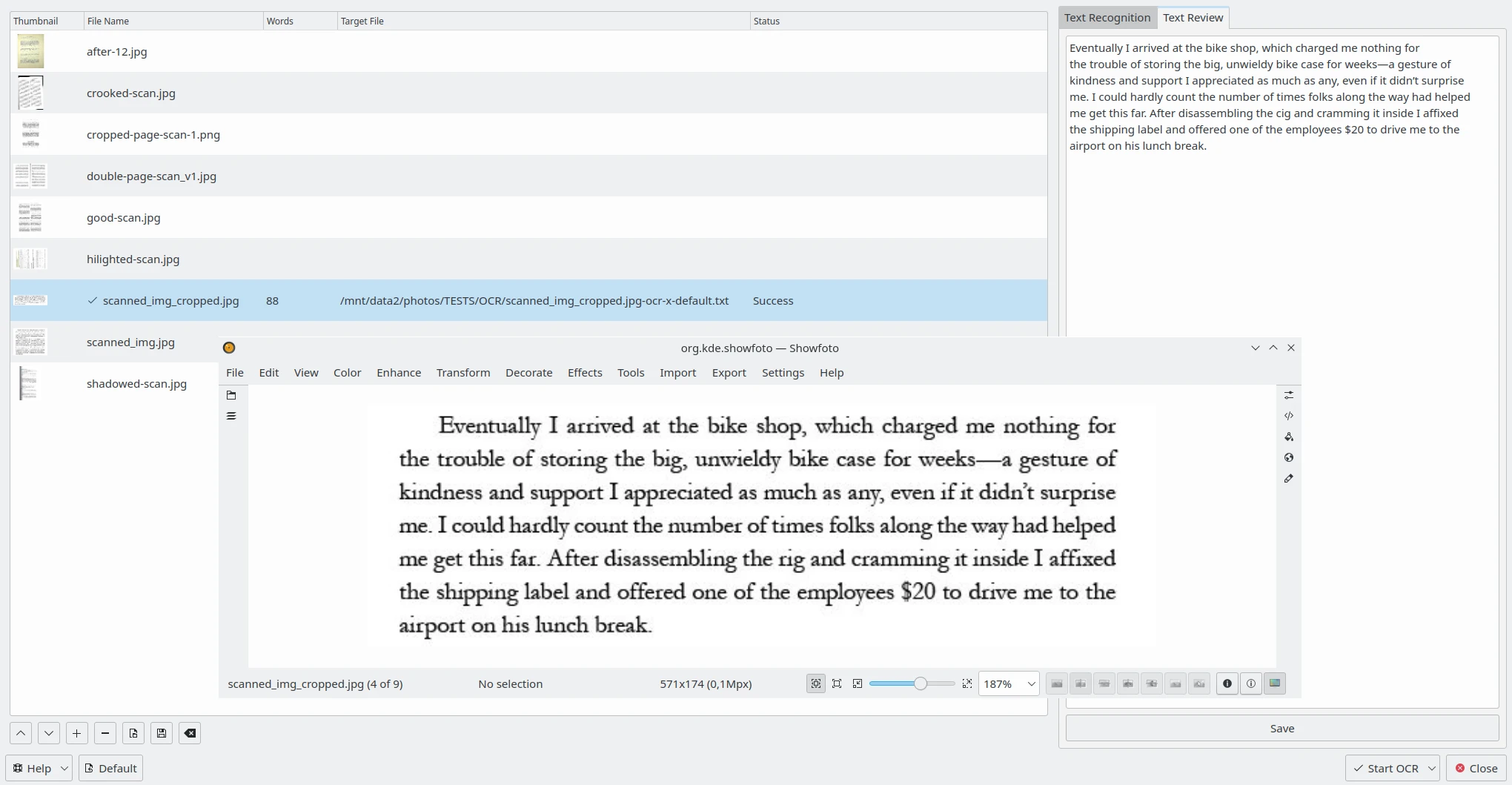
El contingut del convertidor de text OCR en el digiKam per a revisar en el costat dret amb la imatge corresponent oberta en el Showfoto¶