OCR Text Converter¶
The OCR Text Converter tool parses the contents of an image, detects areas with text, and converts that text into editable and translatable characters files.
The tool can perform batch optical character recognition (OCR) over images, and produce translations in many languages using an online translator engine. It also allows you to review the text with the aid of spell checking, and make corrections as needed.
The tool uses the Tesseract, a powerful open-source optical character recognition engine available for Linux, macOS, and Windows.
To perform text conversions, select the scanned images that include text to recognize, and start the tool from the menu , or use the icon OCR Text Converter from the Tools tab on the right sidebar. The following dialog will appear:
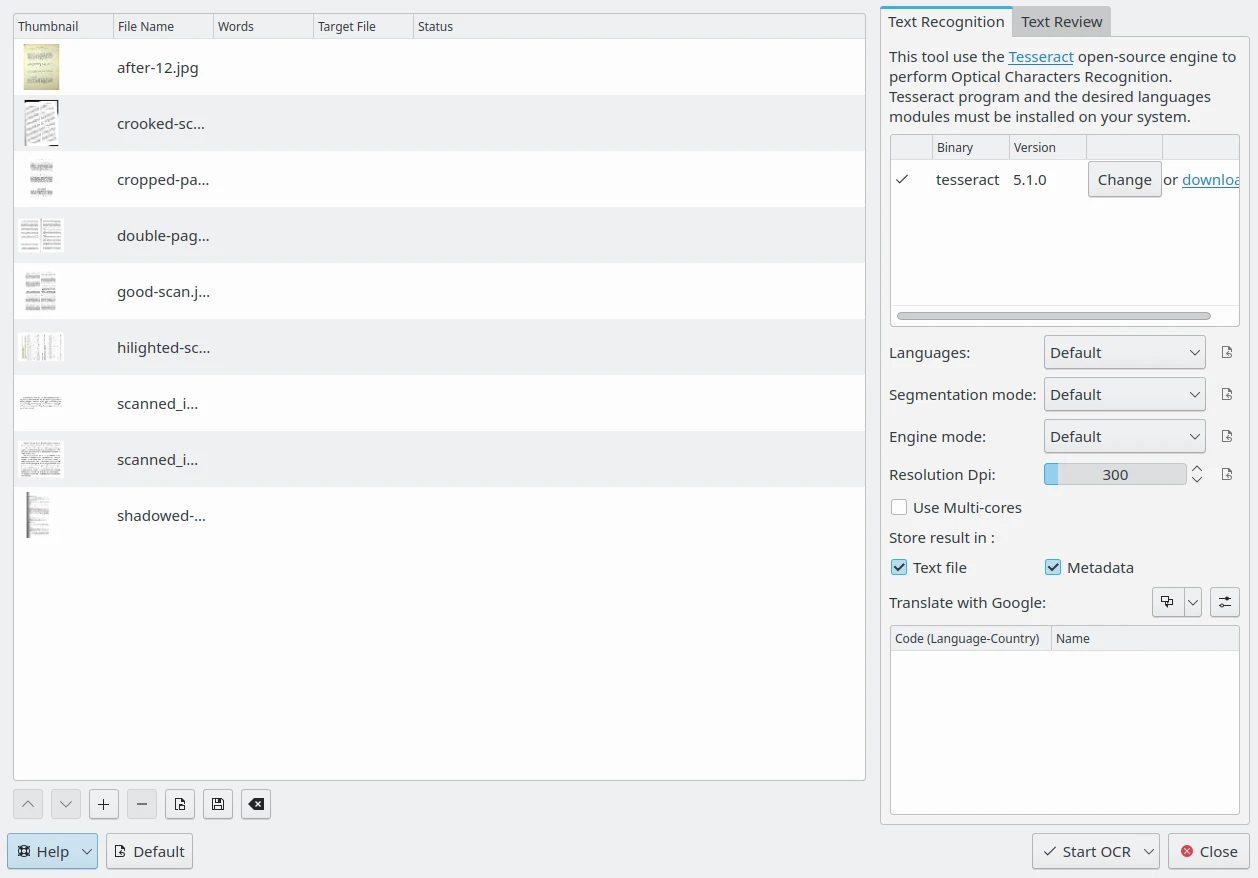
A Janela de Conversão de Texto por OCR do digiKam¶
On the right side, the Text recognition tab indicates whether the Tesseract binary program version is detected on your system. If the binary is not present, you will need to install it onto your system. The lower portion of the Text recognition tab contains the Tesseract options you can set.
The Languages option specifies the language used for OCR. In the Default mode, when processing digital text with multiple languages, Tesseract can automatically recognize languages using Latin alphabets such as English or French, but it’s not compatible with languages using hieroglyphs such as Chinese or Japanese. You can use the Orientation and Script Detection mode instead, or a specific language module if available.
The Segmentation mode option specify the Tesseract page segmentation mode to use while processing images. Possible choices are:
Apenas o OSD: Apenas a detecção de escritas e orientação.
Com o OSD: Segmentação automática das páginas com o OSD.
Sem OSD: Segmentação automática das páginas, mas sem o OSD ou o OCR.
Predefinição: Segmentação completamente automática das páginas, mas sem o OSD.
Coluna de texto: Assume uma única coluna de texto com tamanhos variáveis.
Alinhado verticalmente: Assume um único bloco uniforme de texto alinhado verticalmente.
Bloco: Assume um único bloco uniforme de texto.
Linha: Trata a imagem como uma única linha de texto.
Palavra: Trata a imagem como uma única palavra.
Palavra em círculo: Trata a imagem como uma única palavra num círculo.
Carácter: Trata a imagem como um único carácter.
Texto esparso: Texto esparso. Descobre o máximo de texto possível, sem nenhuma ordem em particular.
Texto esparso + OSD: Texto esparso com OSD.
Linha em bruto: Trata a imagem como uma única linha de texto, ignorando os truques específicos do Tesseract.
Se quiser mais detalhes sobre o Modo de Segmentação do Tesseract, poderá ler este tutorial online.
The Engine mode option specifies the Tesseract OCR internal engine to use while processing images. Possible choices are listed below:
Legacy: Legacy engine only (older engine not based on a neural network).
LSTM: Apenas o motor de redes neuronais LSTM (Long Short-Term Memory deep-learning - aprendizagem por Memória de Curto-Prazo).
Antigo + LSTM: Serão usados tanto o motor antigo como o LSTM.
Predefinição: O valor por omissão. Deixa que o Tesseract escolha o melhor motor com base no que estiver disponível.
The Resolution Dpi option specifies the resolution of the input images, measured in Dots Per Inch (DPI).
If the Use Multi-cores option is enabled, Tesseract will process files from the list in parallel.
The Store result in option specifies where to place the text contents recognized by Tesseract while processing images. Possible choices are:
Ficheiro de texto: Guarda o resultado do OCR num ficheiro de texto separado, na mesma pasta que a imagem processada.
Metadata: Store OCR result in an alternative-language XMP tag in the image metadata.
On the bottom of this view, the OCR result can be translated into different languages using one online translation engine. You can set more than one translation language to process images. Corresponding translations will be hosted in separate text files or in extra metadata entries depending on the Store result in option. See this page from the manual for more details about the Localize Settings.
The Text Review tab on the right side allows you to edit the OCR result for each image processed with Tesseract. Select one item from the list on the left side and the OCR result will be displayed in a text editor. You can edit the text as necessary or apply spell-checking. See this page from the manual for more details about the Spell-Checking Settings.
On the bottom of the dialog, the Default button allows resetting all options to the default values. The Start OCR drop-down button initiates processing of the currently selected images from the list or all items. Finally, the Close button will stop all OCR processes, if any, and close the dialog.
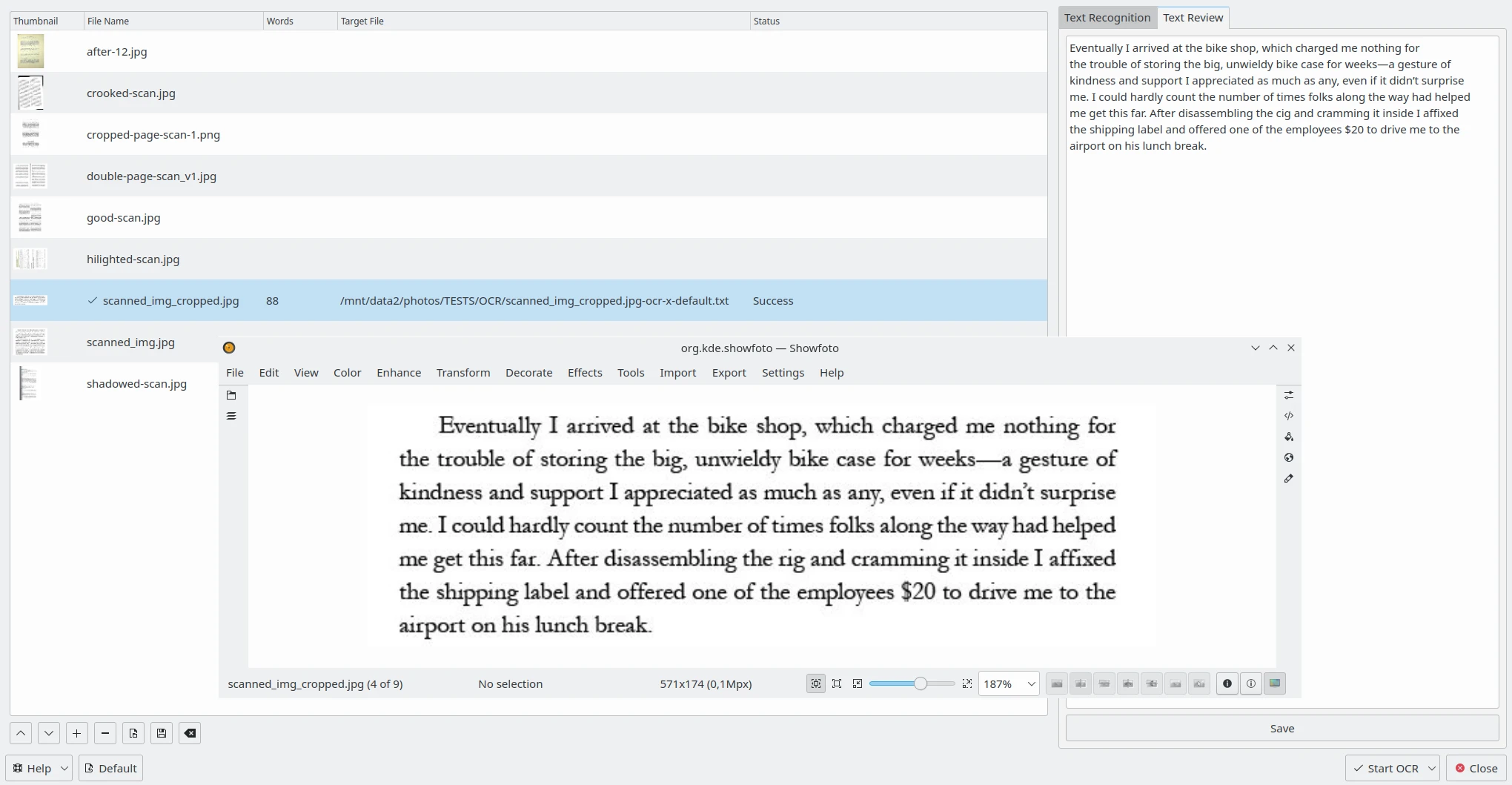
A Conteúdo do Conversor OCR para Texto para Rever no Lado Direito com a Imagem Correspondente Aberta no Showfoto¶