OCR-tekstconverter¶
Het hulpmiddel OCR-tekstconverter ontleedt de inhoud van een afbeelding, detecteer gebieden met tekst en converteert het in leesbare en vertaalbare bestanden met tekens.
Het hulpmiddel kan optische tekenherkenning (OCR) in afbeeldingen in bulk uitvoeren en produceert vertalingen in vele talen met een online vertaal-engine. Het biedt u ook om de tekst te bekijken met de hulp van spellingcontrole en correcties te maken, indien nodig.
Het hulpmiddel gebruikt het open-source hulpmiddel Tesseract, een krachtige engine voor optische tekstherkenning beschikbaar voor Linux, macOS en Windows.
Om tekstconversies te doen, selecteer de gescande afbeeldingen met tekst om deze tekst te herkennen en start het hulpmiddel vanuit het menu of gebruik het pictogram OCR tekstconverter uit het tabblad Hulpmiddelen in de rechter zijbalk. De volgende dialoog zal verschijnen:
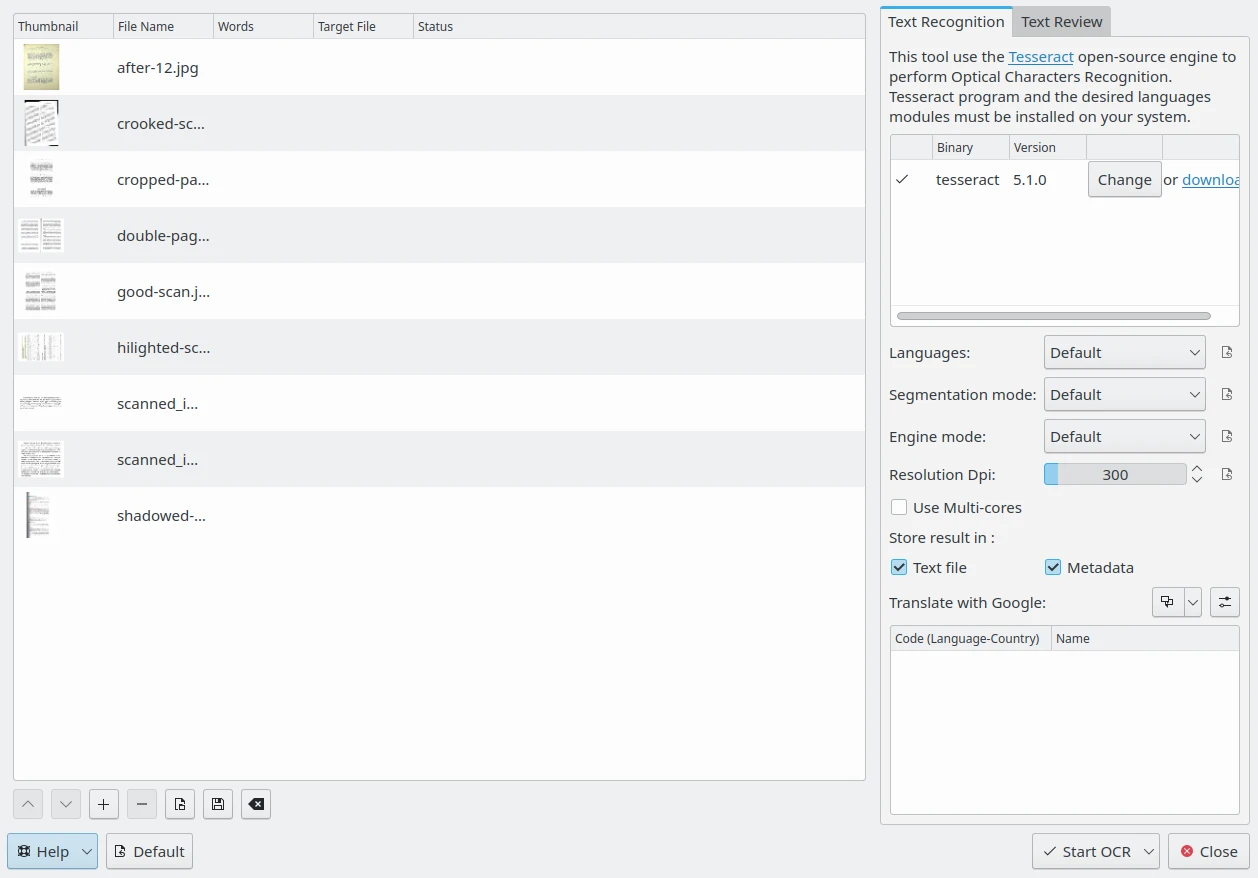
De dialoog van de OCR-tekstconverter van digiKam¶
Rechts geeft het tabblad Tekstherkenning aan of het binaire programma Tesseract gedetecteerd is op uw systeem. Als het binaire programma niet aanwezig is zult u het op uw systeem moeten installeren. Het lagere gedeelte van het tabblad Tekstherkenning bevat de opties van Tesseract die ingesteld kunnen worden.
De instelling Talen specificeert de taal gebruikt voor OCR. In de modus Standaard, wanneer digitale tekst wordt verwerkt in meerdere talen, kan Tesseract automatisch talen met het Latijnse alfabet, zoals Engels of Frans, herkennen maar het is niet compatibel met talen die hiëroglyfen gebruiken zoals Chinees of Japans. U kunt de modus Oriëntatie en scriptdetectie gebruiken, indien beschikbaar, in plaats van een specifieke taalmodule.
De optie Segmentatiemodus specificeert de paginasegmentatiemodus van Tesseract voor gebruik tijdens het verwerken van afbeeldingen. Mogelijke keuzes zijn:
alleen OSD: alleen oriëntatie en detectie van script (OSD).
Met OSD: automatische paginasegmentatie met OSD.
Geen OSD: automatische paginasegmentatie, maar geen OSD of OCR.
Standaard: volledig automatische paginasegmentatie, maar geen OSD.
Kolom met tekst: neemt een enkele kolom met tekst aan met variabele afmetingen.
Verticaal uitgelijnd: neemt een enkel uniform blok aan met verticaal uitgelijnde tekst.
Blok: neem een enkel uniform blok met tekst aan.
Regel: behandel de afbeelding als een enkele tekstregel.
Woord behandel de afbeelding als een enkel woord.
Woord in cirkel: behandel de afbeelding als een enkel woord in een cirkel.
Teken: behandel de afbeelding als een enkel teken.
Dun gezaaide tekst: dun gezaaide tekst. Zoek zo veel mogelijk tekst in geen specifieke volgorde.
Dun gezaaide tekst + OSD: dun gezaaide tekst met OSD.
Ruwe regel: behandel de afbeelding als een enkele tekstregel, met voorbij gaan aan hacks die specifiek Tesseract zijn.
Als u meer details wilt over de Segmentatiemodus van Tesseract, dan kunt u deze online inleiding lezen.
De optie Enginemodus specificeert de interne OCR-engine van Tesseract voor gebruik tijdens het verwerken van afbeeldingen. Mogelijke keuzes zijn:
Verouderd: alleen verouderde engine (oudere engine niet gebaseerd op een neuraal netwerk).
LSTM: alleen neuraal netwerk LSTM (Long Short-Term Memory deep-learning) engine.
Verouderd + LSTM: zowel verouderde als LSTM engines zullen worden gebruikt.
Standaard: standaardwaarde. Laat Tesseract kiezen uit de beste engine gebaseerd op wat beschikbaar is.
De optie Resolutie-dpi specificeert de resolutie van de invoerafbeeldingen, gemeten in Punten per inch (DPI).
Als de optie Meerdere kernen gebruiken is ingeschakeld zal Tesseract bestanden uit de lijst parallel verwerken.
De optie Resultaat opslaan in specificeert waar de door Tesseract herkende tekst wordt opgeslagen tijdens het verwerken van afbeeldingen. Mogelijke keuzes zijn:
Tekstbestand: sla OCR-resultaten op in een apart tekstbestand in dezelfde map als de verwerkte afbeelding.
Metagegevens: sla het OCR-resultaat op in een alternatieve-taal XMP-tag in de metagegevens van de afbeelding.
Onderaan deze weergave kan het OCR-resultaat vertaald worden in verschillende talen met een online vertaalengine. U kunt meer dan één vertaaltaal instellen om afbeeldingen te verwerken. Bij elkaar horende vertalingen zullen opgeslagen worden in aparte tekstbestanden of in extra items metagegevens afhankelijk van de optie Resultaat opslaan in. Zie deze pagina uit de handleiding voor meer details over de Lokalisatie-instellingen.
Het tabblad Tekst herzien rechts biedt u het bewerken van het OCR-resultaat voor elke met Tesseract verwerkte afbeelding. Selecteer één item uit de lijst links en het OCR-resultaat zal getoond worden in een tekstbewerker. U kunt, indien nodig, de tekst bewerken of spellingcontrole toepassen. Zie deze pagina uit de handleiding voor meer details over de Instellingen voor spellingcontrole.
Onderaan de dialoog biedt de knop Standaard het resetten van alle opties naar de standaard waarden. De afrolknop OCR starten initieert het verwerken van de nu geselecteerde afbeeldingen uit de lijst met alle items. Tenslotte, de knop Sluiten zal alle, indien aanwezig, OCR-processen stoppen en de dialoog afsluiten.
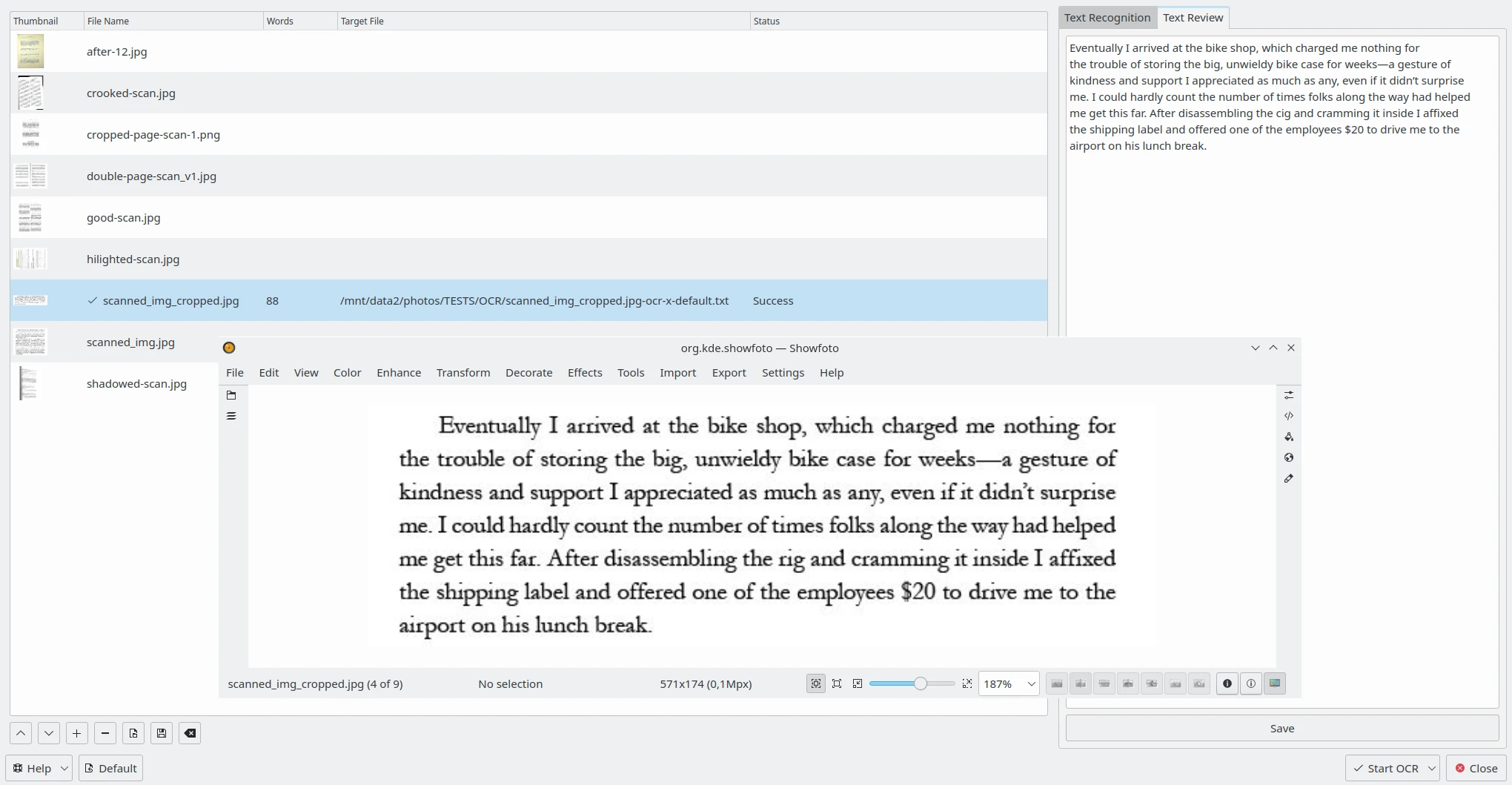
De OCR-tekstconverter van digiKam om de inhoud rechts te herzien met de overeenkomstige afbeelding geopend in Showfoto¶