Assignació automàtica d'etiquetes¶
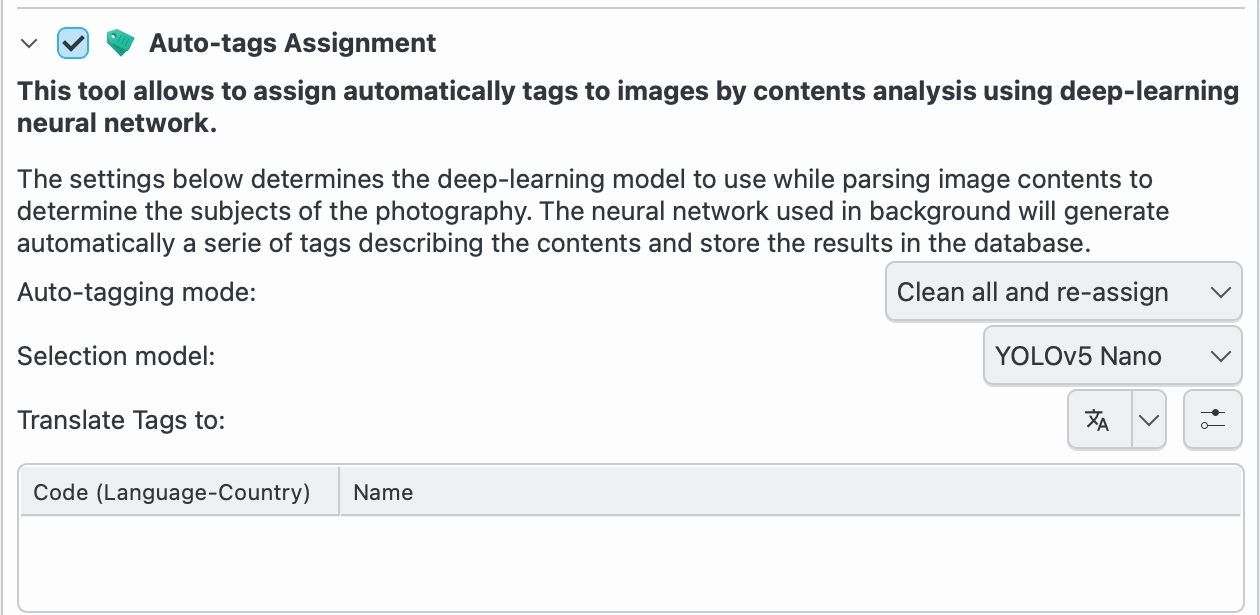
Les opcions de manteniment del digiKam per a l'assignació automàtica d'etiquetes¶
L'Assignació automàtica d'etiquetes explora les imatges de la vostra col·lecció utilitzant una xarxa neuronal que s'ha entrenat per a identificar objectes habituals. Els objectes identificats per la xarxa neuronal s'utilitzen per a etiquetar cada imatge. Quan s'hagi completat l'exploració, podreu cercar a la vostra base de dades imatges que continguin un ocell, una pilota o un cotxe. Les etiquetes generades pel procés Assignació automàtica d'etiquetes estaran amb l'etiqueta auto a la vista Etiquetes per a distingir-les de les etiquetes que s'han assignat manualment.
Aquest procés també és accessible a la vista Etiquetes mitjançant el botó Exploració d'etiquetes automàtiques. Per a més informació sobre les opcions de les Etiquetes automàtiques, vegeu la secció Vista d'etiquetes d'aquest manual.
Per a l'etiquetatge automàtic, hi ha 4 paràmetres que l'usuari pot ajustar per a controlar com el digiKam detecta i etiqueta objectes en una imatge.
Mode d'exploració: el mode d'exploració determina si el digiKam explorarà totes les imatges, o només les imatges que no tinguin una etiqueta auto ja assignada. L'etiqueta auto s'assigna a les imatges que s'han etiquetat automàticament. L'etiqueta auto no està assignada a les imatges que s'han etiquetat manualment.
Mode d'etiquetatge automàtic: en aplicar etiquetes automàtiques, podeu triar entre Actualitza i Substitueix les existents. Actualitza afegirà qualsevol etiqueta automàtica nova a les etiquetes existents a la imatge. Substitueix les existents eliminarà totes les etiquetes automàtiques existents i les substituirà per les etiquetes detectades per l'exploració actual. Qualsevol etiqueta que no estigui amb l'etiqueta auto no es veurà afectada. Aquesta configuració és útil si voleu executar diverses exploracions amb opcions diferents de configuració i combinar els resultats.
Model de detecció: el model de detecció és la xarxa neuronal utilitzada per a detectar objectes a la imatge. El model predeterminat és EfficientNet B7. El model EfficientNet B7 és un model de propòsit general que pot detectar 1.000 objectes i escenes diferents. El model YOLOv11-Nano és més ràpid i utilitza menys memòria que el model EfficientNet B7. El model YOLOv11-Nano es recomana a usuaris amb memòria limitada o processadors més lents, i YOLOv11-XLarge es recomana a usuaris amb més memòria i processadors més ràpids. Tots dos models YOLOv11 estan entrenats per a detectar 80 objectes diferents basats en el conjunt de dades COCO.
Precisió: la configuració de menor precisió pot detectar més objectes en una imatge, però també augmentarà el nombre d'objectes incorrectament identificats (falsos positius). Es recomana la configuració predeterminada de 7 per a l'ús normal.
Mentre el procés d'assignació automàtica d'etiquetes està en marxa, es mostra un indicador de progrés a la cantonada inferior dreta de la finestra principal.